Shared Virtual Memory
This page explains the principles behind HERO’s shared virtual memory (SVM) system and how to write a heterogeneous program for HERO using SVM and OpenMP.
Introduction and SVM Benefits
Shared virtual memory (SVM) allows you as a programmer to exchange virtual address pointers in heterogeneous applications between the host and accelerator. Low-level details such as virtual-to-physical address translation and memory coherence are handled by the system. In this way, SVM
- allows the accelerator to operate on complex, pointer-rich data structures,
- allows programmers to rely on existing host code and libraries for generating and managing shared data structures, and
- paves way for efficient porting of kernels from the host to the accelerator.
Without SVM, programmers must implement a routine that creates a copy of all shared data elements and structures in physically contiguous memory, that adjust all pointers inside the shared data to point to the proper copy, and that ensures memory coherence and consistence whenever execution control is switched between host and accelerator. Since such routines are highly application-kernel dependent, there is no way to include them in a programming model such as OpenMP. Instead, the programmer must rely on custom offloading mechanisms and infrastructure. Moreover, copy-based shared memory not only hampers programmability, but due to extensive data copying it also kills performance.
As such, SVM greatly simplifies programmability of heterogeneous systems. To enable SVM, HERO uses a mixed hardware/software input/ouput mememory management unit (IOMMU) that performs address translation for the accelerators accesses to SVM. In short, the Remapping Address Block (RAB) performs address translation of the accelerators accesses using data from two translation lookaside buffers (TLBs). These TLBs are managed in software on the accelerator by an automatically spawned helper thread that executes the Virtual Memory Management (VMM) library. For more information on the architecture of the SVM system in HERO, please refer to [1] and [2].
Howto
To successfully write a heterogeneous program for HERO using SVM, please adhere to the following points.
Selecting the SVM-Enabled Offload Device
The accelerator has two different device representations in the OpenMP Accelerator Model. Device 0 or BIGPULP_SVM is the SVM-enabled one, whereas device 1 or BIGPULP_MEMCPY uses copy-based offloading using contiguous memory. This one supports only the sharing of buffers, pointers cannot be shared.
To enable SVM, specify the proper device in the OpenMP target directive
#pragma omp target device(BIGPULP_SVM) map(tofrom: YOUR_SHARED_VARIABLES)
Passing Pointers
To pass a pointer to the accelerator, simply put it into the map clause of the target.
For example, to give the accelerator read access to a shared pointer my_ptr, adapt the target to
#pragma omp target device(BIGPULP_SVM) map(to:my_ptr) \
map(tofrom: FURTHER_SHARED_VARIABLES)
Dereferencing Pointers
Finally, the shared pointers can be accessed and dereferenced by the worker threads inside the offloaded kernel.
To make sure the TLBs inside the IOMMU are correctly set up, the worker threads use low-overhead tryread() and trywrite() functions, which are automatically inserted and inlined by the heterogeneous compile toolchain. These functions let the worker threads do the desired memory access and evaluate the response from the IOMMU. In case the TLB contains a valid mapping for the requested virtual address (TLB hit), the worker thread simply continues execution. In the case of a TLB miss, the worker thread goes to sleep. The helper thread then performs a page table walk, updates the TLB and wakes up the sleeping worker thread which can then safely repeat the memory transaction. [1]
NOTE: We are currently in the process of porting the compiler extension that automatically inserts these tryread() and trywrite() functions to the accelerator kernel from GCC 5.2 to 7.1. For now, you have to manually insert these function calls.
For example, to dereference my_ptr and store the value inside a local variable my_var, you need to write
unsigned my_var;
hero_tryread(&my_ptr);
my_var = hero_tryread(my_ptr);
The first tryread ensures the accelerator can successfully read the pointer (it is passed by reference through the OpenMP runtime). The second tryread then dereferences the pointer.
To write a value to a shared variable my_var_shared (don’t forget to add it to the target clause), you need to write
hero_trywrite(&my_var_shared, my_var);
DMA transfers are automatically protected. However, you still need to make sure the accelerator has access to the actual pointer before setting up the DMA transfer:
hero_tryread(&my_ptr);
hero_dma_memcpy(my_ptr,my_local_buffer,XFER_SIZE_B);
NOTE: Do not specify the shared pointer as firstprivate in the very first parallel section as this causes the OpenMP runtime to dereference the pointer without a tryread, which leads to unpredictable behavior.
Full Example Target
The following code snippet is derived from the linked-list application example. The shown kernel traverses a linked list consisting of a custom type vertex
typedef struct vertex vertex;
struct vertex {
unsigned int vertex_id;
unsigned int n_successors;
vertex** successors;
unsigned char payload [PAYLOAD_SIZE_B];
};
and visualized in the figure below.
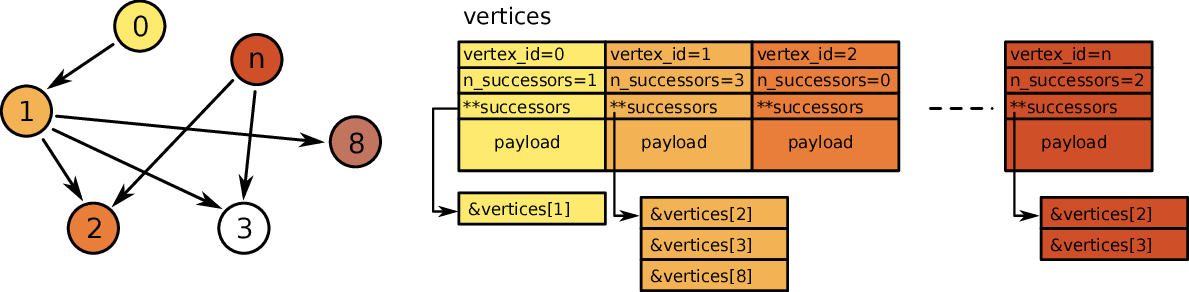
The list is stored inside a vertex array called vertices. Every vertex contains a pointer to a list of successor vertex pointers successors.
The kernel below follows all these successors pointers to determine the number of predecessors (stored in a shared array n_predecessors) of every vertex and then derive the maximum. To speedup execution, the kernel creates a local copy of the shared variables and pointers in the accelerators scratchpad memory (e.g. n_vertices_local, vertices_local). The linked list itself remains however in main memory and is accessed through SVM.
#pragma omp target device(BIGPULP_SVM) \
map(to: vertices, n_vertices) \
map(tofrom: n_predecessors_max, n_predecessors)
{
unsigned n_vertices_local = hero_tryread(&n_vertices);
unsigned n_predecessors_max_local = hero_tryread(&n_predecessors_max);
vertex * vertices_local = hero_tryread(&vertices);
unsigned * n_predecessors_local = hero_l1malloc(n_vertices_local * sizeof(unsigned));
if (n_predecessors_local == NULL) {
printf("ERROR: Memory allocation failed!\n");
}
hero_dma_memcpy(n_predecessors_local, (void *)n_predecessors, \
n_vertices*sizeof(unsigned));
#pragma omp parallel \
firstprivate(vertices_local, n_vertices_local, n_predecessors_local) \
shared(n_predecessors_max_local)
{
unsigned n_successors_tmp = 0;
unsigned vertex_id_tmp = 0;
// get the number of predecessors for every vertex
#pragma omp for
for (unsigned i=0; i<n_vertices_local; i++) {
n_successors_tmp = hero_tryread(&vertices_local[i].n_successors);
for (unsigned j=0; j<n_successors_tmp; j++) {
hero_tryread(&vertices_local[i].successors[j]);
vertex_id_tmp = hero_tryread(&(vertices[i].successors[j]->vertex_id));
#pragma omp atomic update
n_predecessors_local[vertex_id_tmp] += 1;
}
}
// get the max
#pragma omp for reduction(max: n_predecessors_max_local)
for (unsigned i=0; i < n_vertices_local; i++) {
if (n_predecessors_local[i] > n_predecessors_max_local)
n_predecessors_max_local = n_predecessors_local[i];
}
}
hero_trywrite(&n_predecessors_max, n_predecessors_max_local);
hero_dma_memcpy(n_predecessors, n_predecessors_local, n_vertices*sizeof(unsigned));
hero_l1free(n_predecessors_local);
} // target