Occamy
A 432-core, Multi-TFLOPs RISC-V-Based 2.5D Chiplet System for Ultra-Efficient (Mini-)Floating-Point Computation
A 432-core, Multi-TFLOPs RISC-V-Based 2.5D Chiplet System for Ultra-Efficient (Mini-)Floating-Point Computation
Introduction
The Occamy project started as a serendipitous outcome of the Manticore high-performance architecture concept we presented at the Hot Chips conference in 2020 [1,2]. After Hot Chips 2020, the PULP Platform team was approached by GlobalFoundries with an exciting proposal to turn a concept architecture into a real silicon design. The project was made possible by the generous contribution and strong support of GlobalFoundries (technology access, expert advice, ecosystem enablement, and silicon budget), Rambus (HBM2e controller IP and integration support), Micron (HBM2e DRAMs supply and integration support), Synopsys (EDA tool licenses and support) and Avery (HBM2e DRAM verification model). We kick-started the Occamy project on the 20th of April 2021 and taped out the Occamy compute chiplet [3,4] in GlobalFoundries 12nm FinFet technology in July 2022 after less than 15 months of hard work with a team of only <25 people, mostly doctoral students. A few months later, in October, we taped out the passive silicon interposer called Hedwig [5] in GlobalFoundries 65nm technology. Both tape-outs were supported by the Europractice-IC team at Fraunhofer IIS.

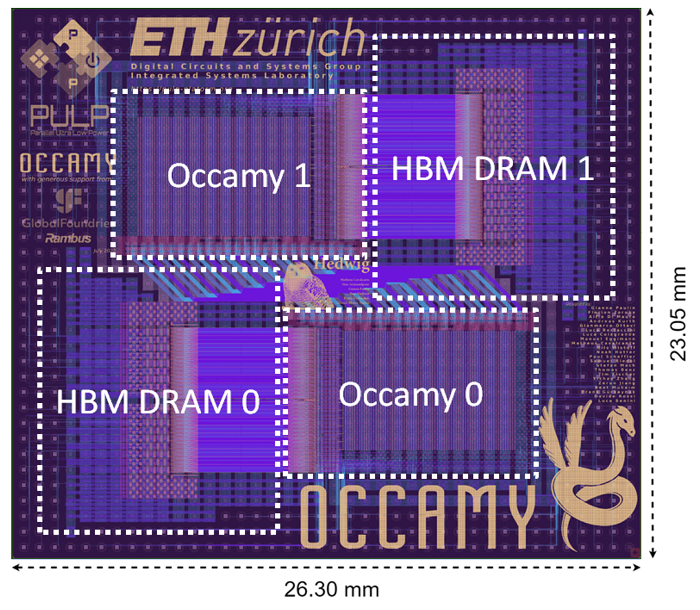
Occamy is a research prototype to demonstrate and explore the scalability, performance, and efficiency of our RISC-V-based architecture in a 2.5D integrated chiplet system showcasing GlobalFoundries' technologies and its IP ecosystem, as well as Rambus' and Micron's IP ecosystem. The research prototype is designed to allow us evaluate and explore the scaling capabilities of our many-core cluster architectures across chiplets coupled with state-of-the-art memory controllers for realistic off-chip data movement overhead. All currently available architecture details and results are pre-silicon estimates. We are waiting for the system to be assembled by our partner Fraunhofer IZM, and we are excited to be soon able to gather (and publish) measured silicon results.
We, the team of PULP Platform, are strong believers in open-source hardware. Hence, we are developing the main chiplet architecture with lots of new ideas completely in the open under the Solderpad Hardware License v0.51 [6]. The only exceptions are the NDA-protected IPs (e.g., Rambus HBM2e controller). All Occamy-related software is released under the Apache-2.0 [7] license.
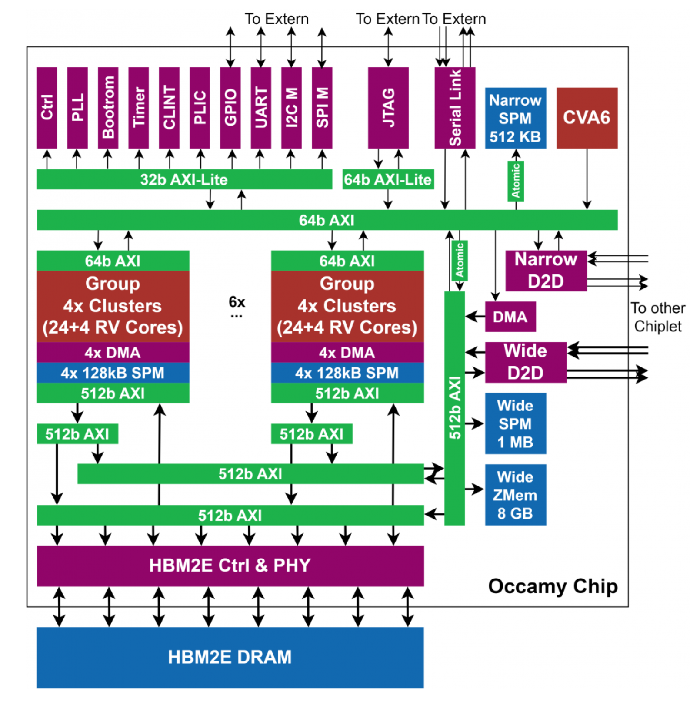
In this work, we combine a small and super-efficient, in-order, 32-bit RISC-V integer core called Snitch [8] with a large multi-precision capable floating-point unit (FPU) enhanced with single instruction multiple data (SIMD) capabilities for the following FP formats: FP64 (11,52), FP32 (8,23), FP16 (5,10), FP16alt (8,7), FP8 (5,2), FP8alt (4,3). In addition to the standard RISC-V fused multiply-accumulate (FMA) instructions, the two 8-bit and two 16-bit FP formats have the new expanding sum-dot-product and three-addend summation (exsdotp, exvsum, and vsum) instructions [9,10].
To achieve ultra-efficient computation on data-parallel FP workloads, two custom architectural extensions are exploited: data-prefetchable register file entries and repetition buffers. The corresponding RISC-V ISA extensions – stream semantic registers (SSRs) [11] and FP repetition instructions (FREP) [7] – enable the Snitch core to achieve FPU utilization higher than 90% for compute-bound kernels. We also designed new extensions for boosting efficiency on sparse data structures [12,13] and stencils, that will be made available in the near future.
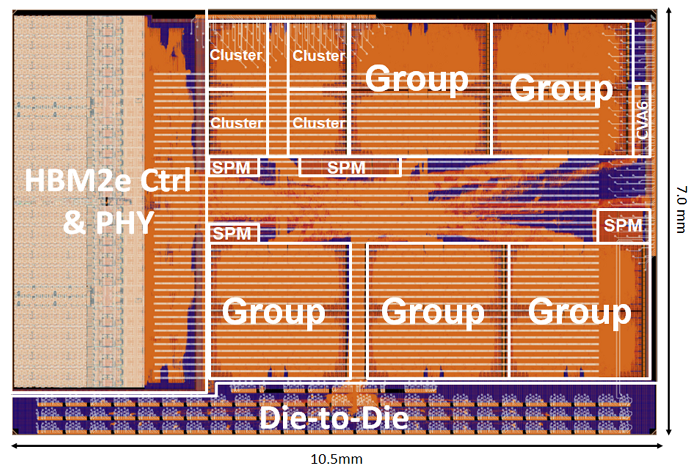
Each chiplet contains more than 216 Snitch cores organized in groups of four compute clusters. Each cluster shares a tightly-coupled memory among eight compute cores and a high-bandwidth (512-bit) DMA-enhanced core orchestrating the data flow. An AXI-based wide, multi-stage interconnect [14] and dedicated DMA engines [15] help manage the massive on-chip bandwidth. A CVA6 Linux-capable RISC-V core [16] manages all compute clusters and system peripherals. Each chiplet has a private 16GB high-bandwidth memory (HBM2e) and can communicate with a neighboring chiplet over a 19.5 GB/s wide, source-synchronous technology-independent die-to-die DDR link. The dual-chiplet Occamy system achieves and estimated peak performances of 0.768 TFLOp/s for FP64, 1.536 TFLOp/s for FP32, 3.072 TFLOp/s for FP16/FP16alt, and 6.144 TFLOp/s for FP8/FP8alt.
More information on Occamy in the context of our HPC work can be found in the following presentations:
- Keynote from Prof. Luca Benini at SC22 – International Conference on High Performance Computing, Networking, Storage and Analysis
Slides:https://pulp-platform.org/docs/BeniniSC11-22.pdf
Video:https://www.youtube.com/watch?v=kMhdq7A3d3I
- Occamy Talk from project lead Gianna Paulin at the workshop "3D Integration: Heterogeneous 3D Architectures and Sensors" at DATE23 – Design, Automation and Test in Europe
Slides: https://pulp-platform.org/docs/date2023/2023-04-19-DATE-3DIC-workshop-v4-pulp-platform.pdf
Recently a number of online resources reported on Occamy. While we are happy that our project received some attention, the authors unfortunately, did not check their articles with us, and consequently, there were several factual errors. While the PULP Platform is working towards RISC-V-based systems for space, Occamy specifically was not developed for space, and the ESA was not involved in the development of Occamy. However, we believe that derivatives of Occamy may find applications in Automotive, Avionics, and Space where high performance and extreme energy efficiency are needed and where RISC-V is very rapidly gaining traction. We are also actively looking at options to collaborate with the ESA in future projects.
Occamy is intended as a research vehicle and not an actual product, at least at this stage. It has been taped out in prototyping quantities, and we expect to have some 10s of functional modules at the end. Exact power and performance numbers will certainly be published and made available as soon as we have the assembled modules back, and our estimations suggest that the power will be in the low 10s of Watts range. As this is a research prototype, we will use our characterization laboratory, which is equipped with a temperature-forcing system to provide the necessary cooling and did not engineer a cooling solution.
The Occamy project builds on a large body of work that we have developed over the past 10 years and was supported in part through several national and European projects, including (but not limited to) Oprecomp H2020 - FET Proactive (#732631), European Processor Initiative (EPI) European High Performance Computing JU under FPA (800928) and special grant agreement 101036168, The European PILOT European High-Performance Computing JU under grant agreement 101034126, “Heterogeneous Computing Systems with Customized Accelerators” project that received funding from the Swiss National Science Foundation under grant number #180625. However, Occamy was not designed directly as part of these projects but rather benefited from our involvement in these projects, which resulted in open-source components that we were able to reuse.
We would once again want to highlight the generous support from our industry partners GlobalFoundries, Rambus, Synopsys, Micron, and Avery, without whom this project would have never been possible!
Many enhanced and new IPs were developed for Occamy, but details on these designs, on silicon implementation and measured post-silicon KPIs are still not published. Stay tuned for many exciting news and publications in the next 12 months.
References
[1] F. Zaruba, F. Schuiki and L. Benini, "A 4096-core RISC-V Chiplet Architecture for Ultra-efficient Floating-point Computing," 2020 IEEE Hot Chips 32 Symposium (HCS), Palo Alto, CA, USA, 2020, pp. 1-24, doi: 10.1109/HCS49909.2020.9220474.
[2] F. Zaruba, F. Schuiki and L. Benini, "Manticore: A 4096-Core RISC-V Chiplet Architecture for Ultraefficient Floating-Point Computing," in IEEE Micro, vol. 41, no. 2, pp. 36-42, 1 March-April 2021, doi: 10.1109/MM.2020.3045564.
[3] G. Paulin, M. Cavalcante, P. Scheffler, Luca B., Y. Zhang, F. Gürkaynak and L. Benini, "Soft Tiles: Capturing Physical Implementation Flexibility for Tightly-Coupled Parallel Processing Clusters," 2022 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Nicosia, Cyprus, 2022, pp. 44-49, doi: 10.1109/ISVLSI54635.2022.00021.
[4] http://asic.ethz.ch/2022/Occamy.html
[5] http://asic.ethz.ch/2022/Hedwig.html
[6] http://solderpad.org/licenses/SHL-0.51/
[7] https://www.apache.org/licenses/LICENSE-2.0
[8] F. Zaruba, F. Schuiki, T. Hoefler and L. Benini, "Snitch: A Tiny Pseudo Dual-Issue Processor for Area and Energy Efficient Execution of Floating-Point Intensive Workloads," in IEEE Transactions on Computers, vol. 70, no. 11, pp. 1845-1860, 1 Nov. 2021, doi: 10.1109/TC.2020.3027900.
[9] S. Mach, F. Schuiki, F. Zaruba and L. Benini, "FPnew: An Open-Source Multiformat Floating-Point Unit Architecture for Energy-Proportional Transprecision Computing," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 29, no. 4, pp. 774-787, April 2021, doi: 10.1109/TVLSI.2020.3044752.
[10] L. Bertaccini, G. Paulin, T. Fischer, S. Mach and L. Benini, "MiniFloat-NN and ExSdotp: An ISA Extension and a Modular Open Hardware Unit for Low-Precision Training on RISC-V Cores," 2022 IEEE 29th Symposium on Computer Arithmetic (ARITH), Lyon, France, 2022, pp. 1-8, doi: 10.1109/ARITH54963.2022.00010.
[11] F. Schuiki, F. Zaruba, T. Hoefler and L. Benini, "Stream Semantic Registers: A Lightweight RISC-V ISA Extension Achieving Full Compute Utilization in Single-Issue Cores," in IEEE Transactions on Computers, vol. 70, no. 2, pp. 212-227, 1 Feb. 2021, doi: 10.1109/TC.2020.2987314.
[12] P. Scheffler, F. Zaruba, F. Schuiki, T. Hoefler and L. Benini, "Indirection Stream Semantic Register Architecture for Efficient Sparse-Dense Linear Algebra," 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 2021, pp. 1787-1792, doi: 10.23919/DATE51398.2021.9474230.
[13] P. Scheffler, F. Zaruba, F. Schuiki, T. Hoefler and L. Benini, "Sparse Stream Semantic Registers: A Lightweight ISA Extension Accelerating General Sparse Linear Algebra," 2023, arXiv: 2305.05559
[14] A. Kurth, W. Rönninger, T. Benz, M. Cavalcante, F. Schuiki, F. Zaruba and L. Benini, "An Open-Source Platform for High-Performance Non-Coherent On-Chip Communication," in IEEE Transactions on Computers, vol. 71, no. 8, pp. 1794-1809, 1 Aug. 2022, doi: 10.1109/TC.2021.3107726.
[15] T.Benz, M. Rogenmoser, P. Scheffler, S. Riedel, A. Ottaviano, A. Kurth, T. Hoefler and L. Benini, "A High-performance, Energy-efficient Modular DMA Engine Architecture," 2023, arXiv: 2305.05240
[16] F. Zaruba and L. Benini, "The Cost of Application-Class Processing: Energy and Performance Analysis of a Linux-Ready 1.7-GHz 64-Bit RISC-V Core in 22-nm FDSOI Technology," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 27, no. 11, pp. 2629-2640, Nov. 2019, doi: 10.1109/TVLSI.2019.2926114.


